やってることや諸注意
対 2021#2 。
基本的にはG検定公式のシラバス(2021/4/15版)をベースにキーワードを拾ってきて調べた。
普通にローカルでもっておけばいいような内容だけど、せっかくブログがあるので記事化した。
G検定とは - 一般社団法人日本ディープラーニング協会【公式】
また、以下のまとめブログが良くまとまっていて使いやすいと思ったので、試験でもチートシートとして使用させていただくことを前提として、こちらの内容で十分と判断したものについては自分のブログ内には記載していない。
【資格試験対策】ディープラーニングG検定【キーワード・ポイントまとめ】 - ITとかCockatielとか
自分用なので、網羅性はありません。
学習中の身なので、内容については保証できません。
今後アップデートの予定はありません。
使える部分があればご自由にどうぞ!
元々の知識がない場合、シラバスの用語を調べてまとめるだけでもだいぶ時間がかかります。試験までの時間が足りなくなってしまったので後半は引用多用、調べきれないキーワードもでてきてしまいました。
調べて理解してまとめようとすると逆にここに書いてある内容ぐらいだったら試験時に調べる必要がなくなったりもします。
なかなか難しいものです。
人工知能とは
人工知能の定義
■AI(人工知能)の定義
現在は研究者によって定義が異なっている。
国内著名者の定義↓↓
AI(人工知能)とは何か? 言葉の意味や定義から機械学習・ディープラーニングまでわかりやすく簡単に解説 | モンスター・ラボ DXブログ
■エージェントアプローチ人工知能による定義
人工知能レベルに同義。
【資格試験対策】ディープラーニングG検定【キーワード・ポイントまとめ】 - ITとかCockatielとか
■推論
機械学習の工程の学習と推論。
入力と出力の相関関係を理解して結果を表示する。単なる予測以上の概念。
人工知能研究の歴史
■特徴量
分析すべき対象データの特徴などを定量化したもの。
説明変数と同じ。
人口知能をめぐる動向
探索・推論
第一次AIブーム。
■αβ法
知識表現
■推移律
Rが関係を表すとき、xRy かつ yRz ならば xRzが成り立つとき、R は推移律を満たすと言う。
・is-a関係
クラス-サブクラスの関係。
「トラック is a 車」、「車 is a 乗り物」であり「トラック is a 乗り物」が成り立つので推移律を満たす。
■ナレッジグラフ
意味ネットワークの一種。
知識の関係性をグラフで表現したもの。
Googleが公表したグラフが原初っぽい。
知識ベース次第で汎用性が高いもの、専門性が高いものにそれぞれ対応できる。
参考:ナレッジグラフ入門
■拡張知能
Augmented Intelligence
もう一つのAI。人間の知見や知能を補助拡張する機会。IBMが定義?
Extended Intelligence
こちらはIEEE、比較的近年の話?
人工知能という言葉のマイナスイメージを払拭する動きか。
機械学習・深層学習
■レコメンデーションエンジン
機械学習の応用例。
そのままにレコメンドを実現するエンジンでよさそう。
レコメンデーションエンジンとは、webサイトやモバイルアプリの利用者や、デジタルチャネルを通じてやり取りしている顧客に対して、適切なオファーや製品、コンテンツを特定し、顧客体験をパーソナライズするためのソフトウェアのことです。
引用元:レコメンデーションエンジンとはどのようなものですか?| アドビ用語集
■コーパス
自然言語処理などで使用される用語集。
ネット・ドキュメントなどから収集した言葉の使い方をまとめたデータベース。
■単純パーセプトロン
発火による情報の入出力を行う人間の神経回路(ニューロン)を参考したモデル。
単一のものを単純パーセプトロン。
多層にしたものを多層パーセプトロン。
イメージ図ではほぼ同様のものに見えるが多層パーセプトロン≠ニューラルネットワークらしい。
活性化関数が異なる。
多層パーセプトロン⇒ステップ関数
ニューラルネットワーク⇒シグモイド関数
参考:パーセプトロンとニューラルネットワーク - 知的好奇心
■OCR
光学文字認識。
活字、手書きテキストの画像を文字コードの列に変換するソフトウェアである。画像はイメージスキャナーや写真で取り込まれた文書、風景写真 (風景内の看板の文字など)、画像内の字幕 (テレビ放送画像内など)が使われる。
■一般物体認識
特に制約のない実世界の1シーン中の画像などの中で、コンピュータが物体を一般名称で認識を行うこと。
過去の機械学習手法では限度があり、ディープラーニングにより飛躍的に精度が向上したものの一つ。
■特徴量エンジニアリング
人間が特徴量を抽出する場合に、特徴量を抽出するために取得済みデータを加工すること。
■表現学習(特徴表現学習)
画像や音声、自然言語から機械により自動的に特徴量を抽出する学習のこと。
基本的にディープラーニングで用いることば。
機械学習の具体的手法
教師あり学習
■ロジスティック回帰
二値分類を行う場合に使用される回帰モデル。
活性化関数にはシグモイド関数が使用される。
また三値以上の多値分類の場合にはソフトマックス関数が使用される。
・シグモイド関数

縦軸は0から1までの値をとる。
・シグモイド関数と二値分割

・ソフトマックス関数
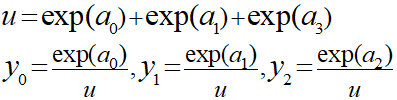
出力値が全て0以上になり、その合計が必ず1になる。
■半教師あり学習
その名の通り、教師あり学習と教師なし学習のハーフ。
学習において正解ラベルが存在するデータとしないデータを使用する。
現実的に正解ラベル付きデータが十分に取得できない場合などに使用される。
https://datachemeng.com/semisupervisedlearningmerit/
■正則化
過学習の防止。
損失関数に学習のペナルティとなる正則化項を加えて、データへの適合性を下げる。
■ノルム
L1ノルムはベクトルa(4,3)が存在するときに距離4と距離3の加算したもののことです。
L2ノルムは同様のベクトルで最短距離で距離5のことです。

■ラッソ回帰 (lasso regression)
L1ノルムの正則化項を加えた回帰直線。
不要なパラメータを削る狙いがある?
■リッジ回帰 (ridge regression)
L2ノルムの正則化項を加えた回帰直線。
過学習を抑える狙いがある?
■アンサンブル学習
弱学習器となる複数の学習モデルを用意し、一つのモデルとして扱う手法のこと。
複数の学習器を通し、複数の結果を統合し最終的な回答を決定する。
・バギング
弱学習器を並列で通して複数の回答を得る。
結果の統合は回帰であれば平均値、分類であれば多数決が一般的。
ランダムフォレストのモデルでもある。
・ブースティング
(≒勾配ブースティング)
弱学習器を直列に通すモデル。
精度の高い結果を得られることも多いが、計算に時間はかかる。
・スタッキング
初段の学習器の出力結果を次段の入力結果とする
引用元:【機械学習】スタッキングのキホンを勉強したのでそのメモ - verilog書く人
仕組みとしてそもそも複雑っぽい。
精度は高いものが作りやすい。収束を早めるなどの効果がある。
・決定木
decision treeとも。
よく見るツリー状のあれ。
グラフでは以下のように対象データを分割するイメージ。
下図だと分岐ごとに分類グループが増えるように見えるが必ずしもそうゆうわけではなく細かく線分を引いて各エリアを詳細に分けていく感じっぽい。
・1分岐

・2分岐

■ランダムフォレスト
分類、回帰、クラスタリングに用いられる。決定木を弱学習器とするアンサンブル学習アルゴリズムであり、この名称は、ランダムサンプリングされたトレーニングデータによって学習した多数の決定木を使用することによる。ランダムフォレストをさらに多層にしたアルゴリズムにディープ・フォレストがある。対象によっては、同じくアンサンブル学習を用いるブースティングよりも有効とされる。
アンサンブル学習のバギングが使用されている。
■ブートストラップサンプリング
データの母集団から重複を許す形でランダムにデータをサンプリングする手法。
ランダムフォレスト(バギング)でのサンプリングに使用される。
■サポートベクトルとマージン
分類の問題を考えたとき、分類を行う境界一番近いデータプロットをサポートベクトル。
サポートベクトルと境界との距離をマージンという。

■サポートベクターマシン(SVM)
マージンを最大化することをコンセプトとした学習モデル。分類と回帰に使用される。
単純な線形回帰分類が困難な場合にカーネル関数を用いて高次元へ写像を行い平面による分類を可能とする。
【資格試験対策】ディープラーニングG検定【キーワード・ポイントまとめ】 - ITとかCockatielとか
⇒異常検知などに使用
■自己回帰モデル
自己回帰モデル(じこかいきモデル、英: autoregressive model)は時点 t におけるモデル出力が時点 t 以前のモデル出力に依存する確率過程である。ARモデルとも呼ばれる。
現在の値を過去のデータを用いて回帰を行うモデル。
VARモデル=Vector Auto Regressiveモデル=ベクトル自己回帰モデル
■疑似相関
2つの事象に因果関係がないのに、見えない要因(潜伏変数)によって因果関係があるかのように推測されること。擬似相関は、客観的に精査するとそれが妥当でないときにも、2つの集団間に意味の有る関係があるような印象を与える。
引用元:擬似相関 - Wikipedia
■adaboost
ブースティングの手法。
参考:AdaBoost - Wikipedia
■剪定
木の枝を切り、形を整えたり風通しをよくすること。
転じて、決定木において特定の箇所以下の枝を切ることにより、分割回数を減らしシンプルし汎用性を上げる。
■スパース
「スパース 」(sparse) とは、「すかすか」という意味だ。「全体のデータは大規模だが、意味のある情報はごく一部しかない」というようなものが、スパース構造を持つデータだ。
引用元:スパースモデリングとは何か?|野口悠紀雄|note
値が0になるデータ多いデータ⇒スパースデータ。
■K近傍法
k近傍法(ケイきんぼうほう、英: k-nearest neighbor algorithm, k-NN)は、特徴空間における最も近い訓練例に基づいた分類の手法であり、パターン認識でよく使われる。最近傍探索問題の一つ。k近傍法は、インスタンスに基づく学習の一種であり、怠惰学習(英語: lazy learning) の一種である。その関数は局所的な近似に過ぎず、全ての計算は分類時まで後回しにされる。また、回帰分析にも使われる。

引用元:k近傍法 - Wikipedia
対象データ(標本)に対してK=Nをとる。
K=3のとき標本は△クラスに分類、K=5のときは□クラスに分類のように考える。
教師なし学習
■デンドログラム
樹形図。
教師なし学習における階層的クラスタリングの手法の一つ。
⇒群平均法。

引用元:クラスター分析の手法②(階層クラスター分析) | データ分析基礎知識
■ウォード法(Ward法)
階層的クラスタリングの一種。
■特異値分解
特異値分解(とくいちぶんかい、英: singular value decomposition; SVD)とは線形代数学における複素数あるいは実数を成分とする行列に対する行列分解の一手法であり、Autonneによって導入された[1][2][3]。悪条件方程式の数値解法で重宝するほか、信号処理や統計学の分野で用いられる[2]。
難しい正直よく分からない時間があったら見直す。
■主成分分析
教師なし学習の手法。PCA。
次元削減を行う手法。
特異値分解もほぼ同じ手法らしい。


2次元データであれば、そのデータの性質をよく表す方向を第一主成分にとり、一次元化する感じか。
■多次元尺度構成法
多次元尺度構成法(たじげんしゃくどこうせいほう、MDS:Multi Dimensional Scaling)は多変量解析の一手法である。主成分分析の様に分類対象物の関係を低次元空間における点の布置で表現する手法である(似たものは近くに、異なったものは遠くに配置する)。
引用元:
多次元尺度構成法 - Wikipedia
■t-SNE
次元削減アルゴリズムの一つ。非線形型の変換を行う。
t-SNEを理解して可視化力を高める - Qiita
■協調フィルタリング
レコメンド機能に用いられる。
例えばユーザの購入履歴からお薦め商品などを表示する際に、他のユーザの購入履歴の類似性を発見し、商品間の相関分析を行う。
■コールドスタート問題
新商品などのデータ蓄積が不十分な場合に、協調フィルタリングによる適切なレコメンドが行えない。
レコメンドの問題だと分かればなんとなく言葉からイメージしやすい。
■コンテンツベースフィルタリング
コンテンツをの特徴をベースに過去にユーザが高く評価したものと比較に同種のコンテンツをレコメンドする。
強化学習
強化学習は全く学んだことがなかったので全体的に弱め。
短時間で正確に深く理解するのは正直不可能だった。。
■強化学習
エージェントがある環境下にあるときの行動の結果に与えられる報酬が最大化するように学習を行う。
囲碁将棋などの最終的に勝ち負けを決めるゲームなどと相性がよい。
■バンディットアルゴリズム
複数の選択肢の中から限られた試行回数でトータルの報酬を最大化するためのアルゴリズム。
・アーム
選択肢のこと
・探索
アームに関する情報を増やすためにアームをひくこと
・活用
現状の情報から最適なアームを引く
A/Bテストがよく引き合いに出される。
バンディットアルゴリズムは探索を繰り返して徐々にチューニングしていく感じか。
■ε-greedy方策
探索時:すべてのアームをランダムに選択
活用時:それまでの試行の結果から、報酬の標本平均\hat{\mu}_{i}の最も高かったアームを選択この方策はシンプルで判りやすいですが、最適な探索回数を見つけるのが困難という課題があり、探索と活用のバランスをうまく調整できないと次のような問題が生じます。
探索が少ない → 最適なアームを発見できず、活用時に最適でないアームを引き続ける可能性がある
探索が多い → 最適でないアームを余分に引いてしまう
引用元:
バンディットアルゴリズム 基本編 | ALBERT Official Blog
■UCB方策
探索回数が少ないアームは引いた結果に得られる報酬の推定が正確に把握できていない可能性が考えられるため、試行回数に応じた補正を取り入れた手法。
詳しくはリンク先などを参照。
■マルコフマルコフ決定過程(MDP)
マルコフ決定過程(マルコフけっていかてい、英: Markov decision process; MDP)は、状態遷移が確率的に生じる動的システム(確率システム)の確率モデルであり、状態遷移がマルコフ性を満たすものをいう。
・マルコフ性
現在の状態から次の状態を予測するとき、現在以外の過去の状態が予測に無関係であるという性質。
■状態価値関数
現在の状態の評価値を算出するみたいな感じか?
参考:今さら聞けない強化学習(1):状態価値関数とBellman方程式 - Qiita
■Q値
強化学習において、ある状態においてある行動をとったときの価値。
短期的な報酬ではなく、長期的な総和をとったときの期待値にあたる。
状態行動価値とも。
■Q学習
状態からの行動に対して発生するQ値をエージェントの行動のたびに更新していく手法。
■TD学習
TD学習(Temporal Difference learning)とは強化学習の手法の一つで、価値ベースの手法です。以下(1)式で表される様にTD誤差が0になる様な行動価値関数を用いてQ値を決定します。
引用元:TD学習とは(Temporal Difference learning) 強化学習理解のための簡単例~制御工学の基礎あれこれ~
Q値が価値だからQ学習が価値ベースというのはなんとなくつながる。
■方策勾配
方策勾配法は、方策をあるパラメタで表される関数とし、そのパラメタを学習することで、直接方策を学習していくアプローチである。
方策を直接扱うことで
・VπやQπを求めるような複雑でメモリを消費する手法を使わなくて良い
・連続空間における行動を扱いやすくなる
などの利点がある。
モデルの評価
■混同行列
予め理解しておいた方がよさそう。
【資格試験対策】ディープラーニングG検定【キーワード・ポイントまとめ】 - ITとかCockatielとか
詳細・算出が必要な場合
混同行列(Confusion Matrix) とは 〜 2 値分類の機械学習のクラス分類について - Qiita
■ROC曲線のAUC
・ROC曲線(Receiver Operating Characteristic Curve)
真陽性率や真陰性率を組み合わせて作成した曲線のこと、とあったが縦軸横軸の取り方はケースバイケースで偽陰性率などをとる場合もあるっぽい。
パターンが変わるとちゃんと分かってないとキツイそうだ。。。
・AUC(Area Under Curve)
曲線下の面積つまりは積分値
機械学習の評価指標 – ROC曲線とAUC | GMOアドパートナーズグループ TECH BLOG byGMO
■オッカムの剃刀
オッカムの剃刀(オッカムのかみそり、英: Occam's razor、Ockham's razor)とは、「ある事柄を説明するためには、必要以上に多くを仮定するべきでない」とする指針。もともとスコラ哲学にあり、14世紀の哲学者・神学者のオッカムが多用したことで有名になった。
■赤池情報量規準
略称 AIC。
赤池情報量規準(あかいけじょうほうりょうきじゅん; 元々は An Information Criterion, のちに Akaike's Information Criterionと呼ばれるようになる)は、統計モデルの良さを評価するための指標である
■代表的な評価関数
M⇒平均、R⇒ルート、L⇒対数、A⇒絶対値
ルート⇒大きな誤差を許容したくない場合
絶対値⇒外れ値の影響を最小限に
対数⇒目的変数と予測値の比率に直目する場合に
・MSE
平均二乗誤差
・RMSE
二乗平均平方根誤差
・MAE
平均絶対誤差
・MSLE
平均二乗対数誤差
・RMSLE
平均二乗対数誤差の平方根
ディープラーニングの概要
ニューラルネットワークとディープラーニング
■誤差逆伝播法
過去記事見直した。
【機械学習】入門⑮ 誤差逆伝搬法(バックプロパゲーション)について学ぶ 理論編 - SEワンタンの独学備忘録
■信用割当問題
ニューラルネットワーク内のどのパラメータが出力層での正解に貢献しているのか、誤差を生じさせているのかを見出すことを信用割当問題(credit assignment problem)と呼びます。つまり、出力の誤差からどう判断してどのパラメータを調節すべきなのかがわからないという問題です。
■DistBelief
深層分散学習のフレームワーク。
並列処理による高速化の機構。Googleが開発。
ディープラーニングのアプローチ
■オートエンコーダ(自己符号化器)
ニューラルネットワークの一種でもある。一般に事前学習に使用される。
分類的には教師なし学習にあたるらしい。異常検知、クラス分類などに使用される。
応用例⇒仮想計測
参考:オートエンコーダとは?事前学習の仕組み・現在の活用方法を解説!!|ITトレンド
オートエンコーダは入力と出力は同じものになり、中間層ではノード数を落とすことで情報をそぎ落としている(エンコード)。一度情報をそぎ落とした状態から元のデータが復元できるようにパラメータを調整する。これは中間層で入力データの特徴を抽出していることに等しい。

・勾配消失を解決する
ニューラルネットワークの中間層を厚くすることで処理能力の向上が見込めるが、バックプロパゲーションの場合、勾配が0に近くなり重みの修正がほとんど起こらなくなってしまう。
オートエンコーダで学習した層をニューラルネットワークの層に仕込むことでこれを防止する。
・過学習の解消
オートエンコーダを通した画像(データ)は入力データと同じものが出力されると記述したが、厳密には復元によって復元される。これは厳密には抽出した特徴より復元するため画像としては入力時よりも粗いものが出力される。
これを利用し、重要度が低い細部をそぎ落とし特徴を抽出したもので学習を行うことにより過学習を防止する。
■積層オートエンコーダ
オートエンコーダを重ねることによって実装する。
オートエンコードのノード数を一層ずつ減らした層を連ねる。
■転移学習
学習済みモデルを別の領域の判定などに活用すること。
特に出力層のみを付け替えることを言う。
■ファインチューニング
転移学習とほとんど同じで最終出力層のみを付け替えるが、学習済みモデルの重みを初期値とし、再度学習することによって微調整する。
■制限付きボルツマンマシン(PBM)
隠れ層と可視化層から構成される無向グラフで表現されるモデル。
■深層信念ネットワーク
確率的モデル。
制限付きボルツマンマシンを取り入れた有向グラフで表現されるモデル。
・有向グラフ:頂点と向きを持つ辺(矢印)により構成されたグラフ
・無向グラフ:頂点と辺により構成されたグラフ
ディープラーニングを実現するには
■GPGPU
GPUの演算資源を画像処理以外の目的に応用する技術のことである。
■TPU
Google社が開発した学習・推論などに特化したGPU。
GoogleのTPUって結局どんなもの? 日本法人が分かりやすく説明:CPU、GPUとの違いとは? - @IT
■CUDA
NVIDIAが開発・提供している、GPU向けの汎用並列コンピューティングプラットフォーム(並列コンピューティングアーキテクチャ)およびプログラミングモデルである。
引用元:CUDA - Wikipedia
活性化関数
■出力層活性化関数
・シグモイド関数
・ソフトマックス関数
■中間層活性化関数
・tanh関数
出力値が-1~1の範囲をとる。微分した場合は最大値1、最小値0

引用元:tanh関数とは ニューラルネットワークで用いる活性化関数~制御工学の基礎あれこれ~
シグモイド関数を微分したときの最大値が0.25であるためそれと比較したときに値が大きいため勾配消失問題が解消される可能性はあるが、値の大小にすぎないので根本的な解決にはならない。
・ReLU関数
0以下の場合は出力値が0、正の場合は入力値がそのまま出力される関数。ランプ関数とも。
微分すると0以下で0、正の場合に1が出力され、勾配消失問題に有効となる。

・グラフ

・微分
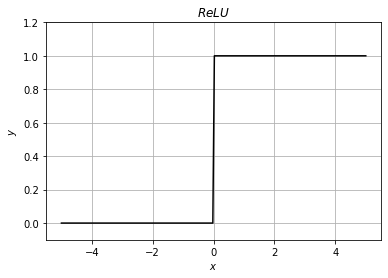
関連記事
【機械学習】入門⑲ KerasによるMNISTの分析 ReLU関数の適用を考える - SEワンタンの独学備忘録
また、シンプルな式による計算速度の向上やスパースデータ生成による精度向上の効果も期待できる。
■Leaky ReLU関数
原則はReLU関数と同じだが、0以下にα(0.01などが使用される)の勾配を持たせ、ReLU関数が0以下で勾配がないために学習が進まなくなる事象を解決するためなどに用いられる。
[活性化関数]Leaky ReLU(Leaky Rectified Linear Unit)/LReLUとは?:AI・機械学習の用語辞典 - @IT
学習の最適化
■勾配降下法
勾配降下法の概念はこの辺を見直した。
【機械学習】入門② Pythonで学ぶ「教師あり学習」 回帰編(線形回帰-勾配降下法) - SEワンタンの独学備忘録
■交差エントロピー
主に分類問題で正解と出力値の誤差を表現するために使用される。
確率分布の相関を表している。
以下は平均交差エントロピー誤差を表す式。

過去記事:【機械学習】入門⑨ 分類-ロジスティック回帰- Pythonで学ぶ「教師あり学習」 - SEワンタンの独学備忘録
■機械学習における学習回数の諸々
・パッチサイズ
1イテレーションで学習に使用するデータ数
・イテレーション
1エポックで実行する学習の実行回数
・エポック
データ分配、学習を行う一連の流れで1エポック

■ 鞍点(あんてん)
学習の際に局所最適解にはまり学習が進まなくなる状態をプラトーという。
三次元のプラトーを鞍点(あんてん)と言い、ある次元では極大点になるがある次元では極小点となるような地点のことを言う。
文字通り鞍のような形になる。

引用元:鞍点 - Wikipedia
■最適化アルゴリズム
局所最適解にハマらないようにするため、効率よく学習を行うために様々なアルゴリズムが提案されている。
- 最急降下法: 全データ を使って損失関数が最小値になるように、勾配を使ってパラメータ更新するよ。
- SGD: データ1つだけ をサンプルして使うことで、最急降下法にランダム性を入れたよ。
- ミニバッチSGD: データを16個とか32個 とか使うことで並列計算できるようにしたSGDだよ。
- モーメンタム: SGDに 移動平均 を適用して、振動を抑制したよ。
- NAG: モーメンタムで損失が落ちるように保証してあるよ。
- RMSProp: 勾配の大きさに応じて 学習率を調整 するようにして、振動を抑制したよ。
- Adam: モーメンタム + RMSProp だよ。今では至る所で使われているよ。
- ニュートン法: 二階微分 を使っているので、ものすごい速さで収束するよ。ただ計算量が膨大すぎて 実用されていない よ。
引用元:
【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法- - Qiita
シラバス的には以下の網羅率が高い。
参考:【資格試験対策】ディープラーニングG検定【キーワード・ポイントまとめ】 - ITとかCockatielとか
リンク先になかったもの。
AdaBound
Adamに学習率の上限と下限を動的に加えたもの
学習前半はAdamのように動き、学習後半からはSGDのように動くもの
AMSBound
AMSGradに学習率の上限と下限を動的に加えたもの
AdaBoundに行った学習率の制限を同じようにAMSGradに組み入れたもの
引用元:[最新論文] 新しい最適化手法誕生! AdaBound & AMSBound - Qiita
基本的なアルゴリズムを0から調べている状態だと理解するのはかなりキツイ。。がリンク先はそれでもイメージだけでも分かるようになっていたと思う。
■ハイパーパラメータ
ハイパーパラメータ(英語:Hyperparameter)とは機械学習アルゴリズムの挙動を設定するパラメータをさします。少し乱暴な言い方をすると機械学習のアルゴリズムの「設定」です。
引用元:https://www.codexa.net/hyperparameter-tuning-python/
具体的にはイテレーションや学習率、隠れ層の数、活性化関数など。
⇒ベイズ最適化:ハイパーパラメータを最適化する方法の一つ。
■ランダムサーチ
ハイパーパラメータの組み合わせをランダムで組み合わせて検証する。
パラメータの候補値が多い場合などはランダムに組み合わせた結果からあたりをつける。
■グリッドサーチ
ハイパーパラメータの候補値を前組み合わせで検証する。
■データリーケージ
データリーケージとは、モデルを作成るときに、本来知らないはずの情報(変数やデータ)を不当に使ってしまうことです。 手元のデータでは高い精度が出たのに、本番環境ではまったく精度が出ない、といった事態になります。
時系列データなどで学習地点では知らない未来データを使用してしまう感じか。
更なるテクニック
■ノーフリーランチの定理
あらゆる問題を効率よく解けるような“万能”の「教師ありの機械学習モデル」や「探索/最適化のアルゴリズム」などは存在しない(理論上、実現不可能)、ということを主張する定理である。
状況に応じてモデルや手法を組み合わせたり、様々な検証を行いなさいってことだろうか。
■二重降下現象
「二重降下現象」は、「CNN」「ResNet」「Transformer」で発生します。パフォーマンスが最初に向上し、次に悪化し、次に「モデルサイズ」「データサイズ」「訓練時間」を増加すると再び向上します。この影響は、「正則化」により回避できることがよくあります。この振る舞いはかなり普遍的であるように見えますが、なぜそれが起こるのかはまだ完全には理解されていません。
■無相関化
白色化に使用される。
要素間の相関関係をゼロになるように線形変換すること。
ディープラーニングの手法
項が重すぎる。。。さらっといきたい。。
この辺は仕組み自体の理解がないときつそうな気もするのである程度は切って多少は分かる部分で得点すべきだろうか。
畳み込みニューラルネットワーク(CNN)
■グローバルアベレージプーリング
Global Average Pooling(GAP)
プーリング処理において、下の層からくる特徴マップの数と分類したいクラスの数を合わせる手法。
パラメータ数の削減により消費メモリの削減や過学習の低減につながる。
■画像データマスク手法
・Cutout
画像中のランダムな位置を中心として正方形領域 (辺の長さは固定) を固定値0でマスクします。
・Random Erasing
大きさがランダムの矩形領域で画像をマスクするのが Random erasing1 です。矩形領域のRGBにはランダムな値 (0〜255となる一様分布で生成) で埋められます。
引用元:画像の一部をマスクするオーグメンテーションのまとめ (Random Erasing, Cutout, Hide-and-Seek, GridMask) - け日記
■複数の画像を組み合わせる手法
・Mixup
・CutMix(CutOutの派生版)
■MobileNet
小型端末専用のモデル。
■Neural ArchitectureSearch(NAS)
ベイズ最適化や遺伝アルゴリズムの類似手法
■NASNet
CNNの畳み込みやプーリングをCNNセルと定義し,CNNセルの最適化を行う
■MnasNet
畳み込みの計算を分割することで,計算量の減少を達成した.
■その他キーワード
Depthwise、Separable、Convolution、EfficientNet
深層生成モデル
■敵対的生成ネットワーク(GAN)
深層生成モデルの一つ。
ジェネレータとディスクリミネータを交互に学習させていくことで、両者を競い合わせるように学習を進めていく。
・ジェネレータ (生成器)
元となるデータやランダムなノイズなどの入力を受け取り、偽物のデータを出力する。
・ディスクリミネータ (識別器)
学習データまたはジェネレータが生成したデータを受け取り、本物か偽物かを判定する。
■GANの生成モデル
・DCGAN
GANのアーキテクチャを利用したモデル。CNNの構造を組み込んでいる。
活性化関数にはLeaky ReLUを採用している。
他にもPix2PixやCycleGANがある。
詳細が必要な場合には以下で多少イメージがつきそう。
CycleGAN:ドメイン関係を学習した画像変換 | NegativeMindException
画像認識分野
■Inceptionモジュール
3つの畳み込みフィルタとmaxプーリングから構成されるモジュール。
1×1、3×3、5×5
同程度の表現力をもつフィルタと比較して、パラメータ数を削減することができる。
■GoogLeNet
Inceptionモジュールを積み重ねるようにして構築したモデル。
2014年ILSVRC。
■VGG
13層の畳み込み層と3層の全結合層から構築されたモデル。
2014年ILSVRC。
■ResNet
層を飛び越えた結合であるSkipconnectionが含まれることが特徴。
2015年ILSVRC。
■Wide ResNet
・フィルタ数をK倍にしたRes Net
・深いネットワークより浅くWideなネットワークの方がパラメータ数は増加するが高精度+高速に学習できる
・Residual Networksの中にDrop outを入れることを提案
ConvNetの歴史とResNet亜種、ベストプラクティス
■DenseNet
ResNetと似た構造を持つ。
前層の全ての出力が後方の層へと入力されるのが特徴。DenseBlock。
参考:DenseNetの論文を読んで自分で実装してみる - Qiita
■SENet
ResNetやInceptionと組み合わせて作り出せるネットワークの総称。
■FPN
Feature Pyramid Network。物体検出に使用されるモデル。
参考:概論&全体的な研究トレンドの概観③(FPN、RetinaNet、M2Det)|物体検出(Object Detection)の研究トレンドを俯瞰する #3 - Liberal Art’s diary
■パノプティックセグメンテーション
画像の分割手法の一つ。
・インスタンスセグメンテーション:画像中の全ての物体に対して、クラスラベルを予測し、一意のIDを付与することを目的とします。
・重なりのある物体を別々に検出する点や、空や道路などの定まった形を持たない物体などはクラスラベルの予測を行わない
・パノプティックセグメンテーション:上の2つのセグメンテーションを組み合わせたタスクです。画像中の全ての画素に対して、クラスラベルを予測し、一意のIDを付与することを目的とします。
■Fast R-CNN
最新のRegion CNN(R-CNN)を用いた物体検出入門 ~物体検出とは? R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN~ - Qiita
■物体検出におけるEncoder–Decoder構造モデル
・SegNet
・U-Net
・PSPNet
■FCN(Fully Convolutional Network)
・Semantic Segmentationにディープラーニングを使った最初の手法がFCN (Fully Convolutional Network)
・Semantic Segmentationは画像をpixel単位でどのクラスに属するか分類する。そのためPixel-labelingとも呼ばれる。
■Dilation convolution
畳み込み先に疎な部分がある構造を定義する。
参考:Dilated Convolution - ジョイジョイジョイ
・Open Pose
カーネギーメロン大学のZhe Caoらが2016年に論文発表した,2D画像の複数人物の姿勢を可視化し,効率的に推定するモデルである。
■その他のキーワード
・Atrousconvolution
・DeepLab
・Parts Affinity Fields
・Mask R-CNN
・矩形領域
音声処理と自然言語処理分野
■LSTM
Long-short term model、RNN (Recurrent Neural Network)の一種。
以下のような記憶ユニットと3つのゲートという構造上の特徴を持つ。
・CEC:過去のデータを保存するためのユニット
・入力ゲート:「前のユニット(1つ前の時間のユニット)の入力をどの程度受け取るか」を調整するためのゲート
・出力ゲート:「前のユニット(1つ前の時間のユニット)の出力をどの程度受け取るか」を調整するためのゲート
・忘却ゲート:「過去の情報が入っているCECの中身をどの程度残すか」を調整するためのゲート
上記のような構造は入力重み衝突や出力重み衝突問題の解消につながる。
また、逆伝播の際に勾配消失問題が起きにくくなっている。
■GRU
LSTMの構造をリセットゲートと更新ゲートという二つの要素にまとめた構造を持つモデル。
LSTMと比較してシンプルな構造を持つため、パラメータ数が削減でき、一般的には学習速度が速くなる傾向がある。
■BackPropagation Through-Time(BPTT)
RNNにおいて、過去の時系列に遡りながら誤差を計算する手法。
■Attention
Attentionとは、連続したデータを扱う際に過去の重要なポイントに着目する(=Attention)ための手法です。イメージ的には質問に回答するときに、相手の質問の中の特定キーワードに注目するといった形です。この例に代表されるように、自然言語処理において広く使用されている手法になります。
引用元:自然言語処理における、Attentionの耐えられない短さ - Qiita
入力から出力を時系列表現で出力するRNN Encoder-Decorder型において、時系列の出力データに対して入力データの中で関連性の高いものを見つける。
■BERT
Google社が開発した自然言語処理モデル。
双方向Transformerによる文章を文頭と文末から学習することによって文脈を解釈することが可能になったと言われる。
大きく2つの主要な技術が使用されている。
・Masked Language Model(MLM)
・Next Sentence Prediction(NSP)
参考:BERTとは|Googleが誇る自然言語処理モデルの仕組み、特徴を解説 | Ledge.ai
■関連キーワード
音韻、フォルマント周波数、音素、メル尺度、局所表現、分散表現、メル周波数ケプストラム係数、A-D変換、パルス符号変調器、高速フーリエ変換、音韻、音素、音声認識エンジン、メル尺度、ワンホットベクトル、局所表現、ELMo、Sour言語モデル、CTC、Source-Target Attention、Encoder-DecoderAttention、Self-Attention、位置エンコーディング、GPT、GPT-2、GPT-3、GLUE、Vision Transformer
深層強化学習分野
■ダブルDQN
・DQN
こちらを確認。
https://sik-bug.hatenablog.com/entry/2020/05/30/103038#-DQNDeep-Q-learning
メインのネットワークとは別のネットワーク(Target network)を作り、ネットワーク更新時に次の状態における行動はメインネットワークで決めるが、その行動の価値評価は別のネットワークで行う。なお別のネットワークには過去のメインネットワークを用いる。
引用元:深層強化学習の簡単な例 〜Double DQN適用〜 - 化学系エンジニアがAIを学ぶ
Q関数の更新を行うネットワークと次の状態のQ関数の更新のうち更新に用いるQ関数を選ぶ。
■デュエリングネットワーク
Dueling Network。
DQNでは行動価値を行動価値関数Qで推定するが、Dueling Networkでは、行動価値関数Qを状態価値関数Vとアドバンテージ関数Aに分解する。
DQNの以前の研究で、状態価値関数とアドバンテージ関数の2つに分解することで、Q学習とよりも速く収束することが示されている。
引用元:リバーシ(オセロ)で深層強化学習 その6(Dueling Network) - TadaoYamaokaの日記
状態のみから計算できる部分と、行動のみから計算できる部分を分けることでQ学習の効率を向上させる。
■深層強化学習の種別
・モデルベース
状態遷移確率や報酬関数で環境に関するモデルが作成できる場合に活用できる。
・方策ベース
価値関数を通さず、方策を直接学習し、期待値の最大化を目指す。
・価値ベース
価値関数をTD学習やモンテカルロ法により学習し、適当な方策に従って行動を決定する。
■関連キーワード
ノイジーネットワーク、アルファゼロ、マルチエージェント強化学習、OpenAI Five、アルファスター、状態表現学習、連続値制御、報酬成型、オフライン強化学習、sim2real、ドメインランダマイゼーション、残差強化学習
モデルの解釈性とその対応
■CAM
Grad-CAMとは【Gradient-weighted Class Activation Mapping】の略で、一言で要約すると予測値に対する勾配を重み付けすることで、重要なピクセルを可視化する技術です。
モデルの軽量化
■関連キーワード
エッジAI、モデル圧縮、量子化、プルーニング
ディープラーニングの社会実装に向けて
AIと社会
■Coursera
スタンフォード大学コンピュータサイエンス教授Andrew NgとDaphne Kollerによって創立された教育技術の営利団体である。世界中の多くの大学と協力し、それらの大学のコースのいくつかを無償でオンライン上に提供している
引用元:コーセラ - Wikipedia
■MOOCs(ムークス)
オンライン講座の総称。
■arXiv
各種学習論文が保存公開されているウェブサイト。
■関連キーワード
AIによる経営課題の解決と利益の創出、法の順守、ビッグデータ、IoT、RPA、ブロックチェーン
AIプロジェクトの進め方
■CRISP-DM
CRISP-DMはCross-Industry Standard Process for Data Miningの略となっており、SPSS、NCRダイムラークライスラー、OHRAなどが中心となって確立されているデータマイニングの方法論。6つのフェーズより構成されており、順番に「Phase1:ビジネスの理解」「Phase2:データの理解」「Phase3:データの準備」「Phase4:モデリング」「Phase5:評価」「Phase6:展開/共有」などのステップが想定されている。

画像引用元:Cross-industry standard process for data mining - Wikipedia
参考:データ分析プロセス『CRISP-DM』とは | DevelopersIO
■MLOps
Machine Learning 操作 (MLOps) は、ワークフローの効率を向上させる DevOps の原則と実践に基づいています。 たとえば、継続的インテグレーション、配信、デプロイです。 MLOps では、次のことを目標に、これらの原則を機械学習プロセスに適用します。
・モデルのより迅速な実験と開発
・実稼働環境へのモデルのより迅速なデプロイ
・品質保証
引用元:MLOps:ML モデル管理 - Azure Machine Learning | Microsoft Docs
DevOpsの拡張概念みたいなものか。実際に機械学習プロジェクトを経験していないとなかなか感覚が難しいかもしれない。
■BPR
普通にビジネスプロセスリエンジニアリングのことだと思われる。
高度に専門化され、プロセスが分断された分業型組織を改革するため、組織やビジネスルールや手順を根本的に見直し、ビジネスプロセスに視点を置き、組織、職務、業務フロー、管理機構、情報システムを再設計し、最終的顧客に対する価値を生み出す一連の改革。
引用元:ビジネスプロセス・リエンジニアリング - Wikipedia
業務プロセス改革⇒抜本的な改革
■プライバシー・バイ・デザイン
PbD:Privacy by Design
カナダ・オンタリオ州情報プライバシーコミッショナーのアン・カブキアン博士が1990年代の半ばに提唱したもので、個人情報をシステムや業務にて「使用する段階」にプライバシー保護の施策を検討するのではなく、その事前段階の「企画・設計段階」から組み込むという考え方です。
引用元:プライバシー・バイ・デザインの実務的な基本概念と重要性|情報センサー2017年11月号 EY Advisory|EY Japan
設計段階でプライバシー保護の取り込みを検討し実行する。
■その他キーワード
クラウド、Web API、データサイエンティスト
データの収集
■オープンデータセット
自由に使えて再利用もでき、かつ誰でも再配布できるようなデータのこと。
個人情報保護法、不正競争防止法、特許法、個別の契約、サンプリング・バイアス、他企業や他業種との連携、産学連携、オープン・イノベーション、AI・データの利用に関する契約ガイドライン
データの加工・分析・学習
■匿名加工情報
法第2条(第9項)
この法律において「匿名加工情報」とは、次の各号に掲げる個人情報の区分に応じて当該各号に定める措置を講じて特定の個人を識別することができないように個人情報を加工して得られる個人に関する情報であって、当該個人情報を復元することができないようにしたものをいう。
第1項第1号に該当する個人情報 当該個人情報に含まれる記述等の一部を削除すること(当該一部の記述等を復元することのできる規則性を有しない方法により他の記述等に置き換えることを含む。)。
第1項第2号に該当する個人情報 当該個人情報に含まれる個人識別符号の全部を削除すること(当該個人識別符号を復元することのできる規則性を有しない方法により他の記述等に置き換えることを含む。)。
引用元:個人情報の保護に関する法律についてのガイドライン(匿名加工情報編) |個人情報保護委員会
単なるマスキングとは微妙に違うっぽい。定められた方法で適切な処置を行った場合に匿名加工情報っぽい。
■カメラ画像利活用ガイドブック
https://www.soumu.go.jp/main_content/000542668.pdf
試験のためだけに確認するにはボリュームがあり効率が良くない。
監視カメラの映像などをビジネスやマーケティングの分析活用に利用する際に個人を特定できるものを気を付ける。
通知などをしろということか。
https://www.meti.go.jp/press/2019/05/20190517001/20190517001-1.pdf
こちらの方が簡易的でイメージはしやすいか。
■ELSI
元々はヒトゲノム計画の中で登場した倫理的・法的・社会的な課題。
気になったら一枚でも確認しておくとよいかも。
https://www.ttc.or.jp/application/files/4115/5348/2680/4-6_TTC-Standardization-Seminar_20180118_r1.pdf
■フィルターバブル
フィルターバブル (filter bubble) とは、「インターネットの検索サイトが提供するアルゴリズムが、各ユーザーが見たくないような情報を遮断する機能」(フィルター)のせいで、まるで「泡」(バブル)の中に包まれたように、自分が見たい情報しか見えなくなること。
レコメンドなどの機能により、自分に適した情報、興味がある情報のみが表示され、それ以外の情報が目に入らなくなる。
■XAI
説明可能なAI。
測定結果や学習・推論プロセスが人により説明可能になっている機械学習モデル。
■関連キーワード
アノテーション、ライブラリ、Python、Docker、Jupyter Notebook、PoC
実装・運用・評価
■データベースの著作物
論文、数値、図形その他の情報の集合物であって、それらの情報を電子計算機を用いて検索する事ができるように体系的に構成したものをいい、コンピュータの検索機能等によりデータベースから特定のデータを抽出できるように、統一的・系統的に整理されたものを指します。
■営業秘密
秘密として管理されている生産方法、販売方法、その他の事業活動に有用な技術上又は営業上の情報であって、公然と知られていないもの」(不正競争防止法第2条6項)。
■限定利用データ
=限定提供データ??
①「業として特定の者に提供する」(「限定提供性」)
②「電磁的方法……により相当量蓄積され」(「相当蓄積性」)
③「電磁的方法により……管理されている」(「電磁的管理性」)
④ 技術上または営業上の情報
⑤ 秘密管理されているものを除くもの
⑥「無償で公衆に利用可能となっている情報と同一」でないこと
引用元:限定提供データについて | IT法務.COM|システム・ソフトウェア・ネットビジネスに関するご相談なら弁護士法人内田・鮫島法律事務所
■GDRP
EUを含む、欧州経済領域内にいる個人の個人データを保護するためのルール。
・個人データの処理、移転(別のサービスでの再利用など)に関する原則
・本人が自身の個人データに関して有する権利
・個人データの管理者や処理者が負う義務
・監督機関設置の規定
・障害発生時のデータの救済と管理者および処理者への罰則
・個人データの保護と表現の自由 など
引用元:GDPRとは?日本企業が対応すべきポイントを考える|セキュリティ対策コラム|情報漏洩防止ソリューション 秘文|日立ソリューションズ
■敵対的な攻撃(Adversarial attacks)
画像、音声、言語などにおいて、特定の細工により意図的にAIに誤認識をさせる。
参考:第2回 ~ AIを騙す攻撃 – 敵対的サンプル - ~
■関連キーワード
著作物、オープンデータに関する運用除外、秘密管理、個人情報、十分性制定→個人データ保護法、フェイクニュース、ディープフェイク、アルゴリズムバイアス、ステークホルダーのニーズ
クライシス・マネジメント
■Partnership on AI
AIの研究団体。
Amazon、Google、DeepMind(Google)、Facebook、IBM、Microsoftのメンバーでスタート。
■シリアス・ゲーム
エンターテイメント以外を目的としたゲーム。
医療、教育、軍事などのシミュレーションを目的としたものなどが有名。
専門家が使用する上記のようなシミュレーションゲームよりも、より一般層をターゲットとしている??
■関連キーワード
内部統制の更新、炎上対策とダイバーシティ、AIと安全保障・軍事技術、実施状況の公開、よりどころとする原則や指針、運用の改善やシステムの改修、次への開発と循環、コーポレートガバナンス
その他追記
■SAEレベル
| SAEレベル | 概要 | 運転操作主体 |
|---|---|---|
| レベル0 | 運転者が全ての動的運転タスクを実行 | 運転者 |
| レベル1 | システムが縦方向又は横方向のいずれかの車両運動制御のサブタスクを運行設計領域において実行 | 運転者 |
| レベル2 | システムが縦方向及び横方向両方の車両運動制御のサブタスクを運行設計領域において実行 | 運転者 |
| レベル3 | システムが全ての動的運転タスクを運行設計領域において実行作動継続が困難な場合は、システムの介入要求等に運転者が適切に応答 | システム(作動継続が困難な場合は運転者) |
| レベル4 | システムが全ての動的運転タスク及び作動継続が困難な場合への応答を限定された運行設計領域において実行 | システム |
| レベル5 | システムが全ての動的運転タスク及び作動継続が困難な場合への応答を領域の限定なく実行 | システム |
引用元:https://www.npa.go.jp/bureau/traffic/selfdriving/kisochisiki1.pdf
レベル0からレベル2までは運転者が一部又は全ての動的運転タスクを実行する。
近年で焦点があたっているのはレベル3あたりで関連法律の改定などが行われている。
■道路交通法
件付きで自動運転を実現するレベル3に対応するため、2020年4月に改正道路交通法が施行
改正法では、自動運行装置を使用した運転も従来の運転に含めることとしたほか、作動状態記録装置が不備な状態での運転を禁止するとともに、データの保存も義務付けている
引用元:自動運転と法律・ガイドライン、日本の現状まとめ | 自動運転ラボ
自動運転機能が正常に動作されている限り、スマートフォンやカーナビの操作が許可されている?
米国ネバダ州では自動運転の走行や運転免許が許可制にて認められた
■自律型致死兵器システム(LAWS: Lethal Autonomous Weapons Systems)
人間の関与なしに自律的に攻撃目標を設定することができ、致死性を有する「完全自律型兵器」を指すと言われているものの、定義は定まっていません。
・関連記事
空飛ぶ殺人ロボット、戦場で使用か AI兵器、世界初?:朝日新聞デジタル
試験対策には新しすぎるか?
統計・数学その他
■関連ワード
ロジットリンク変換
ベイズの定理
尤度
標準化